

C#でHTMLを解析したい場合は「AngleSharp」というライブラリを使うと便利です。
パッケージマネージャーの NuGet からインストールが可能なので Visual Studio を使っている人なら導入も簡単です。
ここでは「AngleSharp」の導入から使い方までを解説します。
NuGetからAngleSharpをインストール
Visual Studio を使っている方なら NuGet を使って簡単にライブラリのインストールが可能です。
メニューから「ツール(T)」→「NuGet パッケージ マネージャー(N)」→「ソリューションのNuGet パッケージ管理(N)...」を選択します。
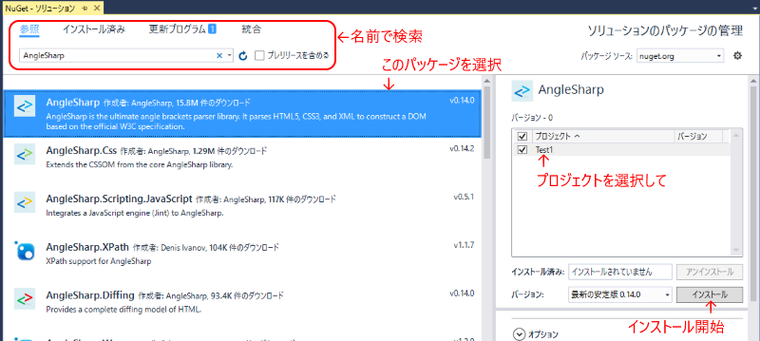
「参照」をクリックしてから検索欄に「AngleSharp」と入力しましょう。
リストの一番上に出てくるパッケージを選択すると右側にインストール画面が出てきます。
右画面の中で適用するプロジェクトにチェックを付けてから「インストール」ボタンをクリックします。
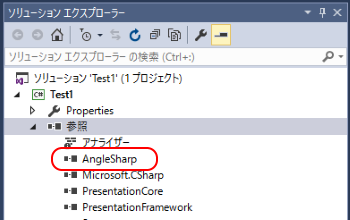
インストールが完了するとソリューションエクスプローラの参照に AngleSharp が追加されます。
HTMLを解析する
HTMLを解析するには AngleSharp.Html.Parser.HtmlParser クラスを使います。
static void Main()
{
ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls | SecurityProtocolType.Tls11 | SecurityProtocolType.Tls12;
WebClient wc = new WebClient();
System.IO.Stream st = wc.OpenRead("https://ja.wikipedia.org/wiki/%E3%83%A1%E3%82%A4%E3%83%B3%E3%83%9A%E3%83%BC%E3%82%B8");
var parser = new AngleSharp.Html.Parser.HtmlParser();
var doc = parser.ParseDocument(st);
var h2Nodes = doc.QuerySelectorAll("h2"); //ドキュメント内すべての<h2>要素を取得
var ulNodes = doc.QuerySelectorAll("ul[id='footer-info']"); //ドキュメント内すべての<ul>要素の中からid属性が'footer-info'の要素を取得
var liNodes = ulNodes[0].QuerySelectorAll("li"); //この要素の直下にある<li>要素を取得
var aNodes = ulNodes[0].QuerySelectorAll("a"); //この要素内のすべて<a>要素を取得
}
HtmlParserクラスのインスタンスを作成し、ParseDocumentメソッドでHTMLデータを解析します。
QuerySelectorメソッドや QuerySelectorAllメソッドを使うと特定の要素を検索して抜き出す事が可能です。抜き出す要素の指定方法は「セレクタAPI」という仕様にしたがって指定します。
セレクタAPI
QuerySelectorメソッドや QuerySelectorAllメソッドの引数は以下のような仕様で指定します。
| 指定例 | 解説 |
| * | 全ての要素を取得する |
|
a
p |
指定したHTML要素を取得する |
|
#ID名 |
指定したIDを持つ要素を取得する |
|
.クラス名 |
指定したクラスを持つ要素を取得する |
|
div > p |
指定要素の直下にある指定要素を取得する ← div要素の直下にある p要素を取得 |
|
div[title='aaa'] div[title^='aaa'] div[title$='aaa'] div[title*='aaa'] |
指定要素で指定の属性をもった要素を取得する ← title属性の値が'aaa'の div要素を取得 ← title属性の値が'aaa'で始まる div要素を取得
← title属性の値が'aaa'で終わる div要素を取得 |
コメントをお書きください